Google's speech recognition API is the Cloud Speech API.
First of all, please apply for "Free Trial" of Cloud Speech API of Google Cloud Platform , and set it so that it can be used.
While reading " Quick Start: Learning in 5 minutes " in the " Google Cloud Speech API Document ", please send the sound described in "sync-request.json" by "curl" and check the procedure by which recognized speech is returned.
| sync-request.json |
{
"config": {
"encoding":"FLAC",
"sampleRateHertz": 16000,
"languageCode": "en-US",
"enableWordTimeOffsets": false
},
"audio": {
"uri":"gs://cloud-samples-tests/speech/brooklyn.flac"
}
}
|
| Send HTTP "Post" request with curl |
C:\Users\nitta\Documents\GoogleSpeech> gcloud auth activate-service-account --key-file=ynitta-XXXXX-XXXXXXXXX.json
Activated service account credentials for: [speech-recognition@ynitta-XXXXX.iam.gserviceaccount.com]
C:\Users\nitta\Documents\GoogleSpeech> gcloud auth application-default print-access-token > token-file.txt
C:\Users\nitta\Documents\GoogleSpeech> curl -s -H "Content-Type: application/json" -H "Authorization: Bearer contents_of_toke-file.txt" https://speech.googleapis.com/v1/speech:recognize -d @sync-request.json
{
"results": [
{
"alternatives": [
{
"transcript": "how old is the Brooklyn Bridge",
"confidence": 0.987629
}
]
}
]
}
|
Get access token and use it to use Google Speech API with HTTP protocol. Please note that if you save the access token by redirect to a file as in the example above, the format of the file will be UTF-16 Encoding of little endian.
gcloud auth application-default print-access-token > token-file.txt |
In order to prevent your access tokens from leaking to others, it is recommended that the file be placed outside Visual Studio project.
[Caution]
You may get an error "Default Credential Authentification ..." when you get the access token.
That is because your
Google Application Default Credentials
is not set well.
The easiest way to get rid of this error is to create a Default_Credentials file by running the following command. When you run the command, the web browser is launched. Since Microsoft is too slow to use in Google Cloud Platform, so we recommend that you might change "Default Application" of "Web Browser" from Microsoft Edge to Google Chrome.
gcloud auth application-default login |
This explanation is not in the Google's "Quick Start" (as of Dec/25/2017), so it seems that there are many people who stumble.
[Caution 2]
You may get an error "Default Credential Authentification ..." when you get the access token.
There is also a way to set the path to the json file (
ynitta-XXXXX-XXXXXXXXX.json
in the above example
) of the downloaded service account in
the GOOGLE_APPLICATION_CREDENTIALS environment variable.
The sound acquired by Kinect V2 is saved as a WAVE file in the following format.
| Property Name | Property Value |
|---|---|
| Format | WAVE_FORMAT_IEEE_FLOAT |
| nChannels | 1 |
| nSamplingPerSec | 16000 |
| wBitsPerSample | 32 |
As the loss less audio formats that can be used in Google Speech API are only FLAC or LINEAR16 (as of Descember/20/2017). So we need to convert our WAVE_FORMAT_IEEE_FLOAT audio data into the above audio data format.
LINEAR16 is the "WAVE_FORMAT_PCM" format in which each audio sampling data is expressed as a 16 bits signed integer of linear value. So, it is easy to convert WAVE_FORMAT_IEE_FLOAT format data into it.
Each data of the WAVE_FORMAT_IEEE_FLOAT format is expressed as a floating point number between -1.0 and 1.0. Each data is aquired by 4 bytes as a 32 bits floating point number, multiply it by 0x7fff = 32767, and convert it to INT16.
| Conversion of audio format (32bit float WAVE --> 16bit int WAVE) |
FLOAT *p = (FLOAT *) pointer ;
INT16 *q = (INT16 *) pointer ;
for (int i=0; i<size/4; i++) {
*q++ = (INT16) (32767 * (*p++));
}
|
Note that the WAVE file saved in "KinectV2_audio" project has 46 bytes of file format information at the beginning of the file and audio data will start thereafter.
The C++ REST SDK (code name "Casablanca") can not be get by NuGet in Visual Studio 2017. Therefore, we will use WinHttp to access the WWW server this time.
JSON data returned by Google Speech API as a result of speech recognition needs to be analyzed separately. In this example, we do not analyze JSON data fo simplicity of explanation.
Right-click on the project name "KinectV2" in the Solution Explorer and select "Properties".
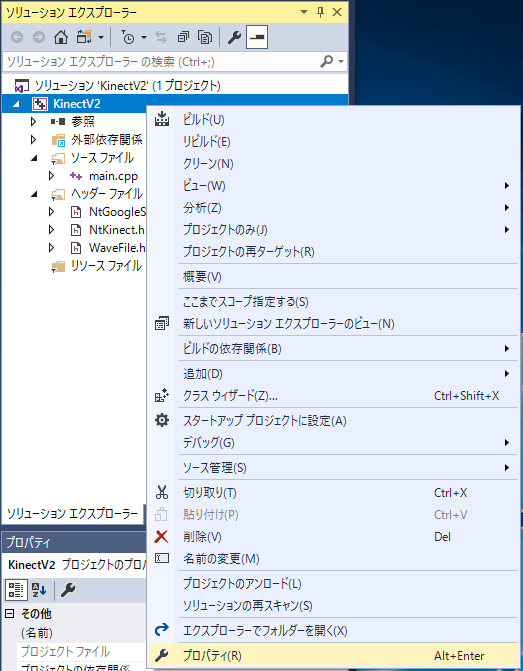
At the "Properties" panel, check "Configuration" is "Release", "Active (Release)" or "All", and check "Platform" is "x64", "Active (x64)" or "All".
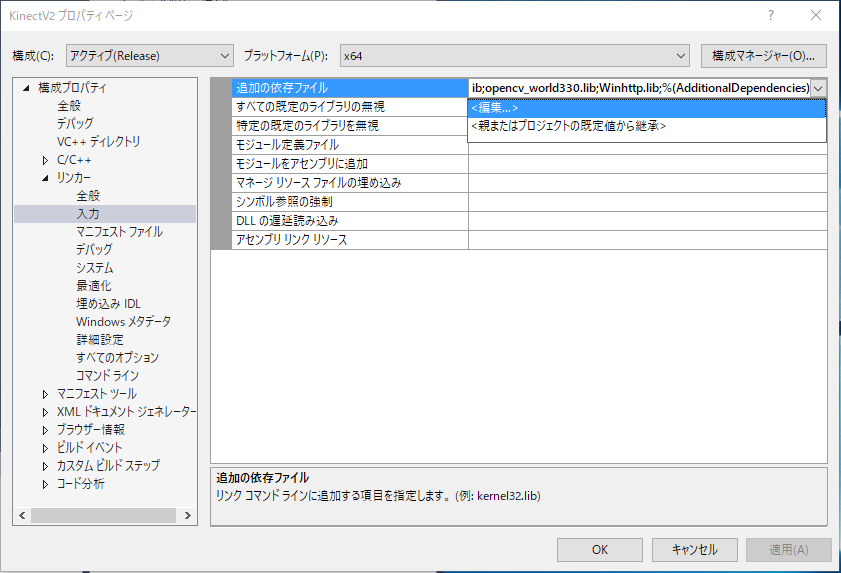
"Configuration Properties" --> "Link" --> "Input" --> "additional dependent files" --> add "Winhttp.lib".

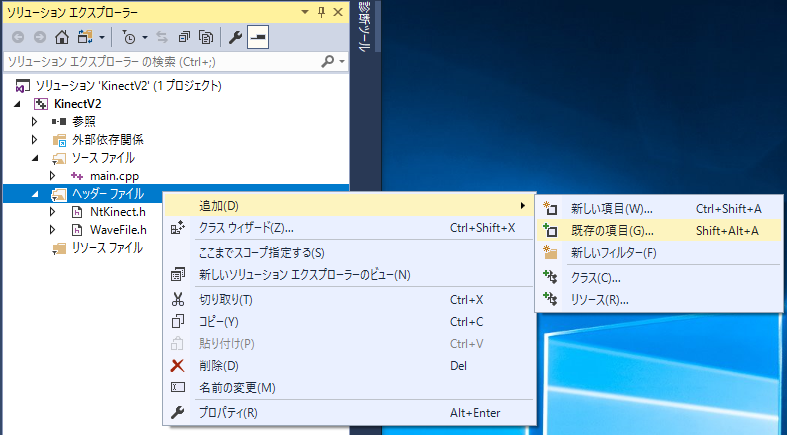

Download the NtGoogleSpeech.h and place it in the folder where other souce files (such as main.cpp) are located. Then, add it to the project.
| NtGoogleSpeech.h |
/*
* Copyright (c) 2017 Yoshihisa Nitta
* Released under the MIT license
* http://opensource.org/licenses/mit-license.php
*/
/* version 0.32: 2017/12/23 */
#pragma once
#include <iostream>
#include <sstream>
#include <string>
#include <vector>
#include <Windows.h>
#include <Winhttp.h>
using namespace std;
class NtGoogleSpeech {
public:
wstring host = L"speech.googleapis.com";
wstring hpath= L"/v1/speech:recognize";
int WaveHeaderSize = 46; /* header size of ".wav" file */
string tokenPath = "";
string accessToken = "";
string getAccessToken() { return getAccessToken(tokenPath); }
string getAccessToken(string path) {
ifstream ifs(path);
if (ifs.fail()) {
stringstream ss;
ss << "can not open Google Speech token file: " << path << endl;
throw std::runtime_error( ss.str().c_str() ); \
}
string token;
ifs >> token;
if (token.length() > 2 && isUtf16(&token[0])) {
vector<char> v;
utf16ToUtf8(&token[0], (int) token.length(), v);
string s(v.begin(), v.end());
token = s;
}
return token;
}
void float32ToInt16(const void* data, int size, vector<char>& v) {
FLOAT *p = (FLOAT *) data; // 4byte for each data
v.resize(size/2);
INT16 *q = (INT16 *) &v[0]; // 2byte for each data
for (int i=0; i<size/4; i++) {
*q++ = (INT16) (32767 * (*p++));
}
return;
}
bool readAll(string path, vector<char>& v) {
v.resize(0);
ifstream ifs(path, std::ios::binary);
if (!ifs) {
cerr << "can not open " << path << endl;
return false;
}
ifs.seekg(0,std::ios::end);
size_t size = ifs.tellg();
v.resize(size);
ifs.seekg(0,std::ios::beg);
ifs.read(&v[0],size);
return true;
}
string syncRequest(char* buf, int size,string locale) {
stringstream ss;
ss << "{" << endl;
ss << " \"config\": {" << endl;
ss << " \"encoding\":\"LINEAR16\"," << endl;
ss << " \"sampleRateHertz\": 16000," << endl;
ss << " \"languageCode\": \"" << locale << "\"," << endl;
ss << " \"enableWordTimeOffsets\": false" << endl;
ss << " }," << endl;
ss << " \"audio\": {" << endl;
ss << " \"content\": \"";
vector<char> v;
float32ToInt16(buf,size,v);
vector<char> u;
base64Encode((char *) &v[0], (int)v.size(),u);
string str(u.begin(), u.end());
ss << str;
ss << "\"" << endl;
ss << " }" << endl;
ss << "}" << endl;
return ss.str();
}
bool utf8ToUtf16(const char *buf, int size, vector<wchar_t>& v) {
unsigned char *p = (unsigned char *) buf;
for (int i=0; i<size; i++) {
UINT16 s0 = ((UINT16) *p++) & 0xff;
if ((s0 & 0x80) == 0) { // 1 byte
v.push_back((wchar_t)s0);
} else {
if (++i >= size) return false;
UINT16 s1 = ((UINT16) *p++) & 0xff;
if ((s1 & 0xc0) != 0x80) return false;
if ((s0 & 0xe0) == 0xc0) { // 2 byte
s0 = ((s0 & 0x1f) << 6) | (s1 & 0x3f);
v.push_back((wchar_t)s0);
} else {
if (++i >= size) return false;
UINT16 s2 = ((UINT16) *p++) & 0xff;
if ((s2 & 0xc0) != 0x80) return false;
if ((s0 & 0xf0) == 0xe0) { // 3 byte
s0 = ((s0 & 0x0f) << 12) | ((s1 & 0x3f) << 6) | (s2 & 0x3f);
v.push_back((wchar_t)s0);
} else {
if (++i >= size) return false;
UINT16 s3 = ((UINT16) *p++) & 0xff;
if ((s3 & 0xc0) != 0x80) return false;
if ((s0 & 0xf8) == 0xf0) { // 4 byte
s0 = (((s0 & 0x07) << 18) | ((s1 & 0x3f) << 12) | ((s2 & 0x3f) << 6) | (s3 & 0x3f)) - (1 << 18);
v.push_back((wchar_t) (0xd800 | ((s0 >> 10) & 0x03ff)));
v.push_back((wchar_t) (0xdc00 | (s0 & 0x03ff)));
} else return false;
}
}
}
}
return true;
}
bool isUtf16(const char *buf) {
unsigned char *p = (unsigned char *)buf;
UINT16 s0 = ((UINT16) *p++) & 0xff;
UINT16 s1 = ((UINT16) *p++) & 0xff;
return (s0 == 0xff && s1 == 0xfe) || (s0 == 0xfe && s1 == 0xff);
}
bool utf16ToUtf8(const char *buf, int size, vector<char>& v) {
v.resize(0);
unsigned char *p = (unsigned char *)buf;
UINT16 s0 = ((UINT16) *p++) & 0xff;
UINT16 s1 = ((UINT16) *p++) & 0xff;
bool le = false;
if (s0 == 0xff && s1 == 0xfe) le = true; // Little Endian
else if (s0 == 0xfe && s1 == 0xff) le = false; // Big Endian
else { cerr << "not utf16" << endl; return false; }
return utf16ToUtf8(buf+2, size-2, v, le);
}
bool utf16ToUtf8(const char *buf, int size, vector<char>& v, bool le) {
if (size %2 == 1) { cerr << "size is odd" << endl; return false; }
unsigned char *p = (unsigned char *)buf;
for (int i=0; i<size/2; i++) {
UINT16 x;
UINT16 s0 = ((UINT16) *p++) & 0xff;
UINT16 s1 = ((UINT16) *p++) & 0xff;
x = (le == true) ? (s1 << 8) + s0 : (s0 << 8) + s1;
if (x < 0x80) v.push_back((char) (x & 0x7f));
else if ((x >> 11) == 0) {
v.push_back((char)(((x >> 6) & 0x1f) | 0xc0)); // 110..... (10-6)th
v.push_back((char)((x & 0x3f) | 0x80)); // 10...... (5-0)th
} else if ((x & 0xf800) != 0xd800) { // Basic Multi-lingual Plane
v.push_back((char)(((x >> 12) & 0xf) | 0xe0)); // 1110.... (15-12)th
v.push_back((char)(((x >> 6) & 0x3f) | 0x80)); // 10...... (11-6)th
v.push_back((char)((x & 0x3f) | 0x80)); // 10...... (5-0)th
} else { // surrogate pair
if (++i >= size/2) {
cerr << "bad surrogate pair" << endl;
return false;
}
s0 = ((UINT16) *p++) & 0xff;
s1 = ((UINT16) *p++) & 0xff;
UINT16 y = (le == true) ? (s1 << 8) + s0 : (s0 << 8) + s1;
if ((x & 0xfc00) != 0xd800 || (y & 0xfc00) != 0xdc00) {
cerr << "bad surrogate pair" << endl;
return false;
}
UINT32 z = ((x & 0x3ff) << 10) + (y & 0x3ff) + (1 << 16); // 21 bits
v.push_back((char)(((z >> 18) & 0x7) | 0xf0)); // 11110... (20-18)th
v.push_back((char)(((z >> 12) & 0x3f) | 0x80)); // 10...... (17-12)th
v.push_back((char)(((z >> 6) & 0x3f) | 0x80)); // 10...... (11-6)th
v.push_back((char)((z & 0x3f) | 0x80)); // 10...... (5-0)th
}
}
return true;
}
bool toUtf8(char *buf, int size, vector<char>& v) {
if (size >= 2 && isUtf16(buf)) {
utf16ToUtf8(buf,size,v);
return true;
} else {
v.resize(size);
for (int i=0; i<size; i++) v[i] = buf[i];
return false;
}
}
void base64Encode(char* buf, int size, vector<char>& v) {
const char table[] = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
v.resize((size/3)*4 + ((size % 3 == 0)? 0 : 4));
for (int i=0; i<size/3; i++) {
UINT32 x = ((UINT32)buf[i*3] << 16) + ((UINT32)buf[i*3+1] << 8) + ((UINT32)buf[i*3+2]);
v[i*4] = table[(x >> 18) & 0x3f];
v[i*4+1] = table[(x >> 12) & 0x3f];
v[i*4+2] = table[(x >> 6) & 0x3f];
v[i*4+3] = table[x & 0x3f];
}
if (size % 3 == 0) return;
int i = size/3;
UINT32 x = ((UINT32)buf[i*3] << 16) + ((size % 3 == 1) ? 0 : ((UINT32)buf[i*3+1] << 8));
v[i*4] = table[(x >> 18) & 0x3f];
v[i*4+1] = table[(x >> 12) & 0x3f];
v[i*4+2] = (size % 3 == 1) ? '=' : table[(x >> 6) & 0x3f];
v[i*4+3] = '=';
}
string doSyncRequest(string path, string locale="ja-JP") {
if (accessToken == "") {
stringstream ss;
ss << "no access token" << endl;
throw std::runtime_error( ss.str().c_str() ); \
}
vector<char> audiodata;
bool flag = readAll(path, audiodata);
if (flag != true) {
cerr << "can not open audio file: " << path << endl;
return "";
}
string json = syncRequest((char *) &audiodata[WaveHeaderSize], (int)audiodata.size()-WaveHeaderSize,locale);
stringstream headers;
headers << "Content-Type: application/json" << endl;
headers << "Authorization: Bearer " + accessToken << endl;
headers << "Content-Length: " << json.size() << endl;
stringstream res;
HINTERNET session = WinHttpOpen(L"Google Speech API/1.0",
WINHTTP_ACCESS_TYPE_DEFAULT_PROXY,
WINHTTP_NO_PROXY_NAME,
WINHTTP_NO_PROXY_BYPASS, 0);
if (session == 0) {
cerr << "WinHttpOpen failed" << endl;
return res.str();
}
HINTERNET conn = WinHttpConnect(session, host.c_str(), INTERNET_DEFAULT_HTTPS_PORT, 0);
if (conn == 0) {
cerr << "WinHttpConnect failed" << endl;
return "";
}
HINTERNET req = WinHttpOpenRequest(conn, L"POST",
hpath.c_str(),
NULL, WINHTTP_NO_REFERER,
WINHTTP_DEFAULT_ACCEPT_TYPES,
WINHTTP_FLAG_SECURE);
if (req == 0) {
cerr << "WinHttpOpenRequest failed" << endl;
return "";
}
string h = headers.str();
wstring wh(h.begin(),h.end());
BOOL result = WinHttpSendRequest(req, wh.c_str(), (DWORD)h.length(),
(LPVOID)json.c_str(), (DWORD)json.length(),
(DWORD)(h.length()+json.length()), 0);
if (result == 0) {
cerr << "WinHttpSendRequest failed" << endl;
return res.str();
}
result = WinHttpReceiveResponse(req, NULL);
if (result == FALSE) {
cerr << "WinHttpReceiveResponse failed " << GetLastError() << endl;
return res.str();
}
DWORD dwSize = sizeof(DWORD);
DWORD dwStatusCode;
result = WinHttpQueryHeaders(req,WINHTTP_QUERY_STATUS_CODE | WINHTTP_QUERY_FLAG_NUMBER,
WINHTTP_HEADER_NAME_BY_INDEX,
&dwStatusCode, &dwSize, WINHTTP_NO_HEADER_INDEX);
res << dwStatusCode << endl;
if (result == FALSE) {
cerr << "WinHttpQueryHeaders failed " << GetLastError() << endl;
return res.str();
}
for (;;) {
DWORD dwSize = 0;
DWORD dwDL = 0;
result = WinHttpQueryDataAvailable(req, &dwSize);
if (result == FALSE) {
cerr << "WinHttpQueryDataAvailable failes " << GetLastError() << endl;
}
if (dwSize == 0) break;
vector<char> buf(dwSize+1);
result = WinHttpReadData(req,(LPVOID) &buf[0], dwSize, &dwDL);
if (result == FALSE) {
cerr << "WinHttpReadData failes " << GetLastError() << endl;
return res.str();
}
string s(buf.begin(), buf.begin()+ dwDL);
res << s << endl;
}
WinHttpCloseHandle(req);
WinHttpCloseHandle(conn);
WinHttpCloseHandle(session);
return res.str();
}
void initialize(string p) {
tokenPath = p;
accessToken = getAccessToken();
}
public:
NtGoogleSpeech() { initialize("C:\\Program Files (x86)\\Google\\Cloud SDK\\token-file.txt"); }
NtGoogleSpeech(string path) { initialize(path); }
~NtGoogleSpeech() { }
};
|
Change the main.cpp to fit your environment.
NtGoogleSpeech gs("C:\\Users\\nitta\\Documents\\GoogleSpeech\\token-file.txt");
|
You must pass the path to the accessToken file of GoogleSpeech to the constructor of NtGoogleSpeech class.
| main.cpp |
#include <iostream>
#include <sstream>
#define USE_AUDIO
#include "NtKinect.h"
#include "NtGoogleSpeech.h"
using namespace std;
#include <time.h>
string now() {
char s[1024];
time_t t = time(NULL);
struct tm lnow;
localtime_s(&lnow, &t);
sprintf_s(s, "%04d-%02d-%02d_%02d-%02d-%02d", lnow.tm_year + 1900, lnow.tm_mon + 1, lnow.tm_mday,
lnow.tm_hour, lnow.tm_min, lnow.tm_sec);
return string(s);
}
void doJob() {
NtKinect kinect;
bool flag = false;
string filename = "";
NtGoogleSpeech gs("C:\\Users\\nitta\\Documents\\GoogleSpeech\\token-file.txt");
std::wcout.imbue(std::locale("")); // for wcout
while (1) {
kinect.setRGB();
if (flag) kinect.setAudio();
cv::putText(kinect.rgbImage, flag ? "Recording" : "Stopped", cv::Point(50, 50),
cv::FONT_HERSHEY_SIMPLEX, 1.2, cv::Scalar(0, 0, 255), 1, CV_AA);
cv::imshow("rgb", kinect.rgbImage);
auto key = cv::waitKey(1);
if (key == 'q') break;
else if (key == 'r') flag = true;
else if (key == 's') flag = false;
else if (key == 'u' || key == 'j') {
if (filename != "") {
string res = gs.doSyncRequest(filename,(key == 'u')? "en-US" : "ja-JP");
vector<wchar_t> u16;
if (gs.utf8ToUtf16(&res[0],(int)res.length(),u16)) {
wstring w16(u16.begin(),u16.end());
std::wcout << w16 << endl;
} else {
cout << res << endl;
}
string outname(filename.begin(), filename.end()-4);
ofstream fout(outname+".txt");
fout << res;
}
}
if (flag && !kinect.isOpenedAudio()) {
filename = now() + ".wav";
kinect.openAudio(filename);
} else if (!flag && kinect.isOpenedAudio()) kinect.closeAudio();
}
cv::destroyAllWindows();
}
int main(int argc, char** argv) {
try {
doJob();
}
catch (exception &ex) {
cout << ex.what() << endl;
string s;
cin >> s;
}
return 0;
}
|
Start recording with 'r' key and stop recording with 's' key. As for the file name, we acquire the time at the record starting and create a wav file with it as a file name (eg. "2016-07-18_09-16-32.wav"). Use the 'j' key or 'u' key to send the most recently recorded voice to the Google Speech API and save the analysis result to a file with extension ".txt". 'u' key will recognize speech as English ("en-US") and 'j' key as Japanese ("ja-JP").
The character string returned by speech recognition is utf-8. If Japanese recognition result are displayed as they are, it may appear as garbled characters depending on the environment.
Recording starts with 'r' key, and stops with 's' key. Recording status is displayed as "Recording" or "Stopped" at the upper left of the RGB image.
Use the 'j' key or 'u' key to recognize the latest recorded voice as Japanese or English.
The number (eg. 200, 401) displayed before recognition result json is the status code of HTTP access.
Recognition result of 2017-12-20_18-57-05.wav as "en-US".| 2017-12-20_18-57-05.txt |
200
{
"results": [
{
"alternatives": [
{
"transcript": "good morning",
"confidence": 0.9117151
}
]
}
]
}
|
| 2017-12-20_18-57-21.txt |
200
{
"results": [
{
"alternatives": [
{
"transcript": "おはよう",
"confidence": 1
}
]
}
]
}
|
| In case of expired access token |
401
{
"error": {
"code": 401,
"message": "Request had invalid authentication credentials. Expected OAuth 2 access token, login cookie or other valid authentication credential. See https://developers.google.com/identity/sign-in/web/devconsole-project.",
"status": "UNAUTHENTICATED"
}
}
|
Since the above zip file may not include the latest "NtKinect.h", Download the latest version from here and replace old one with it.