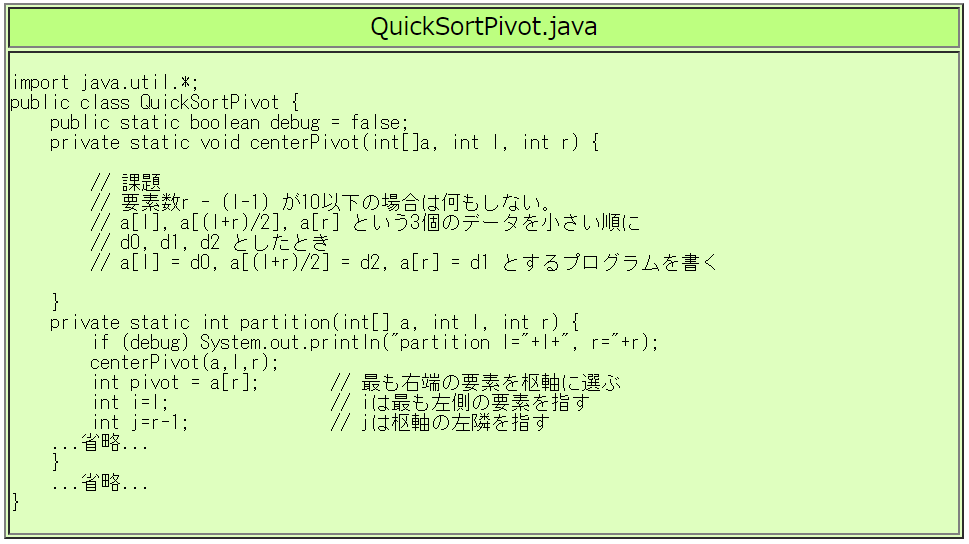
$ javac QuickSort.java$ java QuickSort