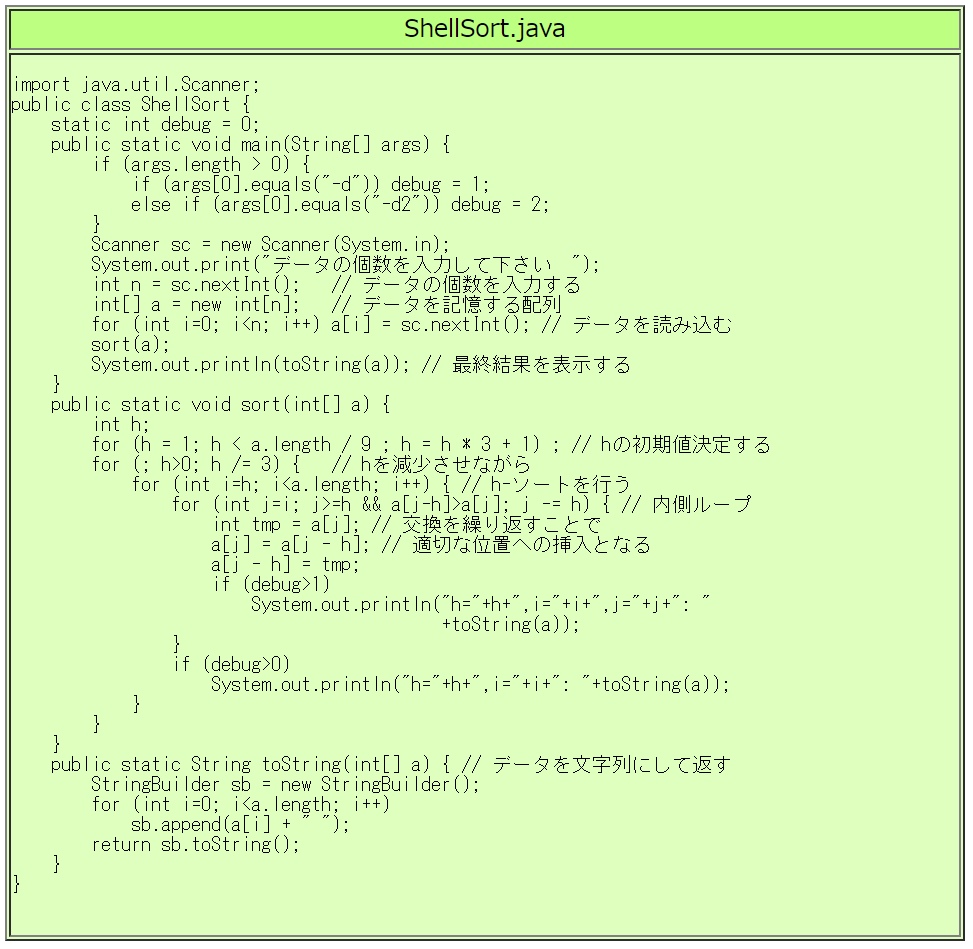
$ javac ShellSort.java$ java ShellSort -d

