線形探索の計算量は $O(n)$ ですが、二分探索法 (Binary Search) の 計算量は $O(\log n)$ です。
二分探索法では、データは大きい順番、または小さい順番に並んでいます。 注目する領域の真中のデータが、探索するデータよりも大きいか、小さいかで 探索領域を次々に半分にしていきます。
二分探索法で10個のデータから、「14」というデータを探索する様子を 下に示します。 表の中では、注目する領域の下が l (low), 上が h (high)、 真中が m (middle) で表されています。
| 配列番号 | a[0] | a[1] | a[2] | a[3] | a[4] | a[5] | a[6] | a[7] | a[8] | a[9] |
| 配列データ | 1 | 3 | 4 | 8 | 13 | 14 | 18 | 20 | 21 | 25 |
| 初期状態 | ↑l | ↑m | ↑h | |||||||
| 2回目 | ↑l | ↑m | ↑h | |||||||
| 3回目(発見) | ↑l ↑m |
↑h |
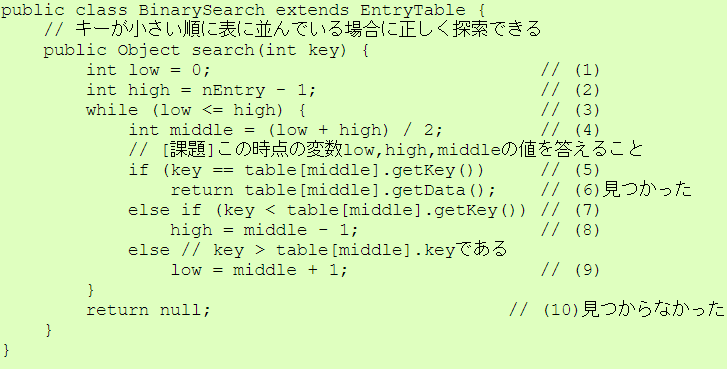
下に示す BinarySearch.java のプログラムにおいて、探索の部分の 計算量を考えてみましょう。
繰り返しの回数は以下のように計算できます。
データの総数を $n$ とおくと、繰り返しの度に high と low で囲む領域は
半分になりますから、繰り返し回数を $m$ とすると
$\quad 2^m = n$
両辺の $\log_e$ を計算すると
$\displaystyle \quad m \log_e 2 = \log_e n$
$\displaystyle \quad \therefore ~~ m = \frac{\log_e n}{\log_e 2}$
$\log_e 2$ は定数なので、繰り返しの回数は
$\log n$ のオーダーになります。
| (1) (2)の計算量 | $O(1)$ |
| (3)〜(9)の計算量 | $O(\log n)$ |
| (10)の計算量 | $O(1)$ |
| 二分探索法 BinarySearch.java |
|
|
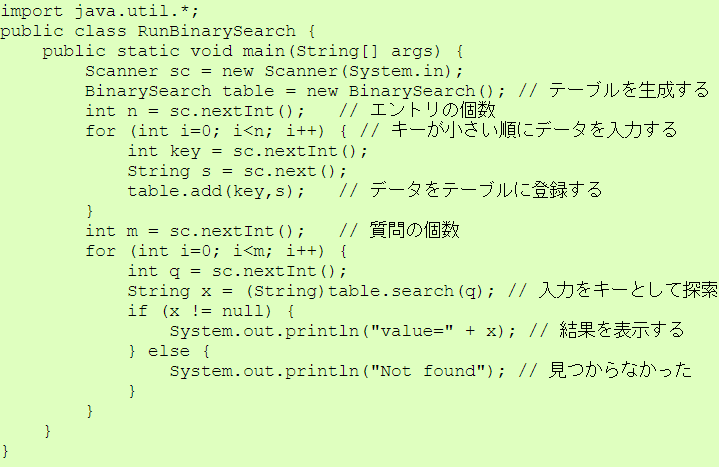
| RunBinarySearch.java |
 |
| RunBinarySearch.javaの実行例 |
% javac RunBinarySearch.java % java RunBinarySearch 10 2 two 4 four 5 five 8 eight 13 thirteen 14 fourteen 18 eighteen 20 twenty 21 twenty-one 26 twenty-six 4 1 Not found 32 Not found 3 Not found 20 value=twenty |
RunBinarySearch.javaが扱うデータは次の形式です。
最初の行には1個の整数 $N$ が含まれる。 $N$ はデータの数 (ただし $1 \leqq N \leqq 100$ ) を表す。
2行目以降は $N$ 行に渡ってデータが続く。 各行は 「1個の整数 $K_i$」、 「データの区切りとしての1個の空白文字」、 「1個の文字列 $D_i$」 を含む (ただし $1 \leqq i \leqq N$ )。 $K_i$ はデータのうち「比較の対象となるキー」であり、 $D_i$ は「それ以外のデータ」である。
ただし$i \lt j$ ならば $K_i \leqq K_j$ が成り立つとする(つまりキーが小さい方から大きい方に順に並んでいるデータが与えられる)。
その次の行は、質問の個数を表す整数 $M$ を含む( $1 \leqq M \leqq 10$ )。 それ以降に $M$ 行続き、各行は探索すべきキーとなる整数 $Q_j$ (ただし $1 \leqq j \leqq M$ ) を含む。
二分探索法では、データは大きさの順番に並んでいることが必要です。 したがって、データを登録する毎に以下の計算量が必要となります。
| (1)データを挿入すべき位置を計算する | $O(\log n)$ |
| (2)その位置より後のデータをずらす | $O(n)$ |
| (3)その位置にデータを登録する | $O(1)$ |
データを1個登録するには、$O(n)$ の計算量が必要です。 すなわち、データを $n$ 個登録するには、$O(n^2)$ の計算量が必要である、ということになります。
ただし、データを最初にまとめて登録する場合は、もう少し効率のよい方法が使えます。 データ1個をキーの大きさに関係なく(順番ばらばらに)登録する計算量は $O(1)$ なので、 $n$ 個のデータを順番ばらばらに登録する計算量は $O(n)$ となります。 最後に一度だけ整列(sort、最も効率のよいアルゴリズムだと$O(n \log n)$で可能)を行えば、 全体として $O(n \log n)$ で整列したデータ全体が得られます。
データがn個の場合の計算量は、アルゴリズムによって以下のように 変化します。
| アルゴリズム | 登録 | 探索 |
|---|---|---|
| 線形探索法 | $O(n)$ | $O(n)$ |
| 二分探索法 | $O(n^2)$ または $O(n \log n)$ | $O(\log n)$ |
一般に、データの探索回数の方が登録回数よりも多くなりますので、 そのような場合は線形探索法よりも二分探索法の方が効率がよくなります。 ただし、「探索途中で頻繁にデータの登録がある場合は、二分探索法は向かない」 ことになります。
どのようなアルゴリズムが「適切である」かは、 データの大きさやプログラムの利用法によって異なります。 理由を以下に示します。
作成したプログラムが正しく動作することを確認したら、それぞれの 提出先に提出しなさい。 提出した後は、正しく提出されていることを http://nw.tsuda.ac.jp/class/algoA/local/handin/ で必ず確認しておいて下さい。 提出〆切は次回の講義の開始時刻です。
| 提出ファイル | BinarySearch.java |
|---|---|
| コメント欄: | 指定箇所の通過回数と、各時点における変数low, high, midの値 |
| 提出先: | 「宿題提出Web:アルゴリズムA:課題2a」 http://nw.tsuda.ac.jp/class/algoA/local/handin/up.php?id=kadai2a |
RunBinarySearch.java を動作させて下さい。 Entry.java, EntryTable.java, BinarySearch.java, RunBinarySearch.java が必要となります。
10個の入力データと4個の質問のデータを
| 10個の入力データ | 4個の質問データ |
| |
// [課題]この時点の変数low,high,middleの値を答えること
BinarySearch.javaを提出して下さい。 ただし、提出する際のコメント欄には各質問に対する上記の考察の 結果を記述すること。
[解答例]
質問のキー:6の場合
4回通過する。
low=0, high=9, middle=4
low=0, high=3, middle=1
low=2, high=3, middle=2
low=3, high=3, middle=3
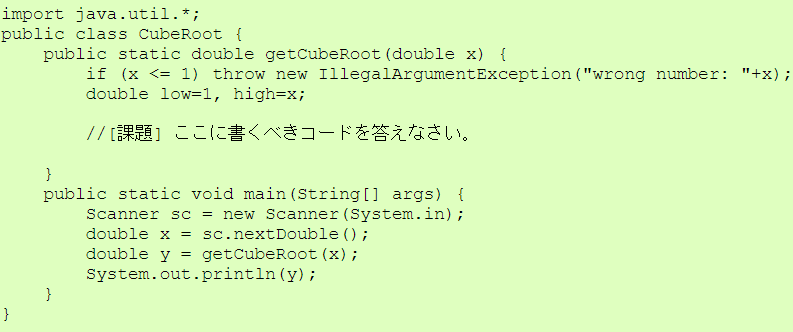
| 提出ファイル | CubeRoot.java |
|---|---|
| コメント欄: | CubeRoot.javaに2, 8, 100, 1000, 123456789を入力として与えたときのそれぞれの出力 |
| 提出先: | 「宿題提出Web:アルゴリズムA:課題2b」 http://nw.tsuda.ac.jp/class/algoA/local/handin/up.php?id=kadai2b |
与えられた実数 x の立方根(3乗根, 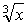 )を計算するプログラムを作成しなさい。
与えられる実数 x の値は1より大きいと仮定して構わない。
答に含まれる誤差は1.0×10-5よりも小さいこと。
ただし、Mathクラスのメソッドを使ってはならない。
)を計算するプログラムを作成しなさい。
与えられる実数 x の値は1より大きいと仮定して構わない。
答に含まれる誤差は1.0×10-5よりも小さいこと。
ただし、Mathクラスのメソッドを使ってはならない。
(ヒント)2分法を使えばよい。 最初は low=1.0, high=x と置いて、lowとhighの真ん中 midの3乗と x を比較する。比較した結果、lowとhighの区間を1/2ずつ狭めていって high-lowが許容誤差よりも小さくなったら終了する。
| CubeRoot.java |
|
| CubeRoot.javaの実行例 |
$ javac CubeRoot.java |
| low | high | middle | middle^3 | xとの比較 |
|---|---|---|---|---|
| 1.0 | 8.0 | 4.5 | 91.125 | > |
| 1.0 | 4.5 | 2.75 | 20.796875 | > |
| 1.0 | 2.75 | 1.875 | 6.591796875 | < |
| 1.875 | 2.75 | 2.3125 | 12.366455078125 | > |
| 1.875 | 2.3125 | 2.09375 | 9.178558349609375 | > |
| 1.875 | 2.09375 | 1.984375 | 7.813961029052734 | < |
| 1.984375 | 2.09375 | 2.0390625 | 8.477964878082275 | > |
| 1.984375 | 2.0390625 | 2.01171875 | 8.141450583934784 | > |
| 1.984375 | 2.01171875 | 1.998046875 | 7.976585380733013 | < |
| 1.998046875 | 2.01171875 | 2.0048828125 | 8.058736917562783 | > |
| 1.998046875 | 2.0048828125 | 2.00146484375 | 8.017591002746485 | > |
| 1.998046875 | 2.00146484375 | 1.999755859375 | 7.997070670113317 | < |
| 1.999755859375 | 2.00146484375 | 2.0006103515625 | 8.007326454151553 | > |
| 1.999755859375 | 2.0006103515625 | 2.00018310546875 | 8.002197466796815 | > |
| 1.999755859375 | 2.00018310546875 | 1.999969482421875 | 7.999633794650407 | < |
| 1.999969482421875 | 2.00018310546875 | 2.0000762939453125 | 8.00091556226879 | > |
| 1.999969482421875 | 2.0000762939453125 | 2.0000228881835938 | 8.000274661346351 | > |
| 1.999969482421875 | 2.0000228881835938 | 1.9999961853027344 | 7.999954223720124 | < |
| 1.9999961853027344 | 2.0000228881835938 | 2.000009536743164 | 8.000114441463666 | > |
| 1.9999961853027344 | 2.000009536743164 | 2.000002861022949 | 8.000034332324503 | > |
| ループから抜ける | ||||
| 1.9999961853027344 | 2.000002861022949 | 1.9999995231628418 | 7.999994277955466 | < |