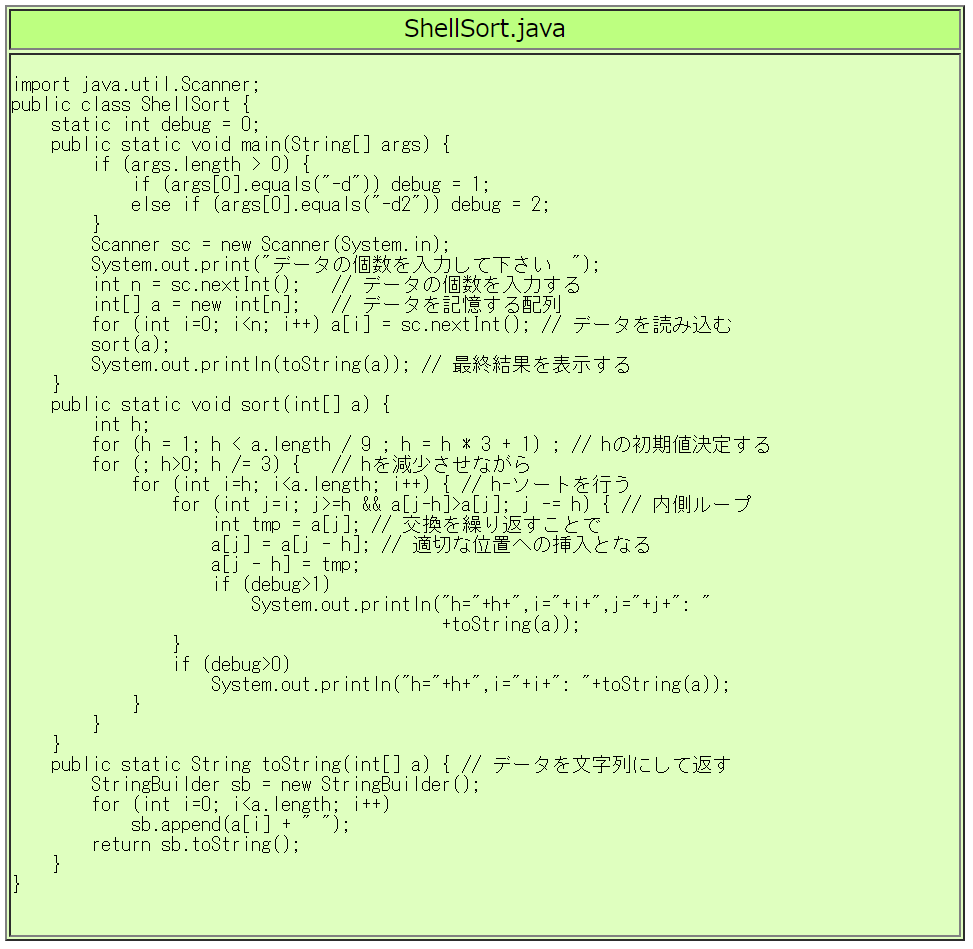
$ javac ShellSort.java  $ java ShellSort -d
データの個数を入力して下さい 18
11 3 16 7 13 4 9 17 2 5 12 8 15 1 18 10 6 14
h=4,i=4: 11 3 16 7 13 4 9 17 2 5 12 8 15 1 18 10 6 14
h=4,i=5: 11 3 16 7 13 4 9 17 2 5 12 8 15 1 18 10 6 14
h=4,i=6: 11 3 9 7 13 4 16 17 2 5 12 8 15 1 18 10 6 14
h=4,i=7: 11 3 9 7 13 4 16 17 2 5 12 8 15 1 18 10 6 14
h=4,i=8: 2 3 9 7 11 4 16 17 13 5 12 8 15 1 18 10 6 14
h=4,i=9: 2 3 9 7 11 4 16 17 13 5 12 8 15 1 18 10 6 14
h=4,i=10: 2 3 9 7 11 4 12 17 13 5 16 8 15 1 18 10 6 14
h=4,i=11: 2 3 9 7 11 4 12 8 13 5 16 17 15 1 18 10 6 14
h=4,i=12: 2 3 9 7 11 4 12 8 13 5 16 17 15 1 18 10 6 14
h=4,i=13: 2 1 9 7 11 3 12 8 13 4 16 17 15 5 18 10 6 14
h=4,i=14: 2 1 9 7 11 3 12 8 13 4 16 17 15 5 18 10 6 14
h=4,i=15: 2 1 9 7 11 3 12 8 13 4 16 10 15 5 18 17 6 14
h=4,i=16: 2 1 9 7 6 3 12 8 11 4 16 10 13 5 18 17 15 14
h=4,i=17: 2 1 9 7 6 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=1: 1 2 9 7 6 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=2: 1 2 9 7 6 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=3: 1 2 7 9 6 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=4: 1 2 6 7 9 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=5: 1 2 3 6 7 9 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=6: 1 2 3 6 7 9 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=7: 1 2 3 6 7 8 9 12 11 4 16 10 13 5 18 17 15 14
h=1,i=8: 1 2 3 6 7 8 9 11 12 4 16 10 13 5 18 17 15 14
h=1,i=9: 1 2 3 4 6 7 8 9 11 12 16 10 13 5 18 17 15 14
h=1,i=10: 1 2 3 4 6 7 8 9 11 12 16 10 13 5 18 17 15 14
h=1,i=11: 1 2 3 4 6 7 8 9 10 11 12 16 13 5 18 17 15 14
h=1,i=12: 1 2 3 4 6 7 8 9 10 11 12 13 16 5 18 17 15 14
h=1,i=13: 1 2 3 4 5 6 7 8 9 10 11 12 13 16 18 17 15 14
h=1,i=14: 1 2 3 4 5 6 7 8 9 10 11 12 13 16 18 17 15 14
h=1,i=15: 1 2 3 4 5 6 7 8 9 10 11 12 13 16 17 18 15 14
h=1,i=16: 1 2 3 4 5 6 7 8 9 10 11 12 13 15 16 17 18 14
h=1,i=17: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
[nitta@ni java]$ java ShellSort -d2
データの個数を入力して下さい 18
11 3 16 7 13 4 9 17 2 5 12 8 15 1 18 10 6 14
h=4,i=4: 11 3 16 7 13 4 9 17 2 5 12 8 15 1 18 10 6 14
h=4,i=5: 11 3 16 7 13 4 9 17 2 5 12 8 15 1 18 10 6 14
h=4,i=6,j=6: 11 3 9 7 13 4 16 17 2 5 12 8 15 1 18 10 6 14
h=4,i=6: 11 3 9 7 13 4 16 17 2 5 12 8 15 1 18 10 6 14
h=4,i=7: 11 3 9 7 13 4 16 17 2 5 12 8 15 1 18 10 6 14
h=4,i=8,j=8: 11 3 9 7 2 4 16 17 13 5 12 8 15 1 18 10 6 14
h=4,i=8,j=4: 2 3 9 7 11 4 16 17 13 5 12 8 15 1 18 10 6 14
h=4,i=8: 2 3 9 7 11 4 16 17 13 5 12 8 15 1 18 10 6 14
h=4,i=9: 2 3 9 7 11 4 16 17 13 5 12 8 15 1 18 10 6 14
h=4,i=10,j=10: 2 3 9 7 11 4 12 17 13 5 16 8 15 1 18 10 6 14
h=4,i=10: 2 3 9 7 11 4 12 17 13 5 16 8 15 1 18 10 6 14
h=4,i=11,j=11: 2 3 9 7 11 4 12 8 13 5 16 17 15 1 18 10 6 14
h=4,i=11: 2 3 9 7 11 4 12 8 13 5 16 17 15 1 18 10 6 14
h=4,i=12: 2 3 9 7 11 4 12 8 13 5 16 17 15 1 18 10 6 14
h=4,i=13,j=13: 2 3 9 7 11 4 12 8 13 1 16 17 15 5 18 10 6 14
h=4,i=13,j=9: 2 3 9 7 11 1 12 8 13 4 16 17 15 5 18 10 6 14
h=4,i=13,j=5: 2 1 9 7 11 3 12 8 13 4 16 17 15 5 18 10 6 14
h=4,i=13: 2 1 9 7 11 3 12 8 13 4 16 17 15 5 18 10 6 14
h=4,i=14: 2 1 9 7 11 3 12 8 13 4 16 17 15 5 18 10 6 14
h=4,i=15,j=15: 2 1 9 7 11 3 12 8 13 4 16 10 15 5 18 17 6 14
h=4,i=15: 2 1 9 7 11 3 12 8 13 4 16 10 15 5 18 17 6 14
h=4,i=16,j=16: 2 1 9 7 11 3 12 8 13 4 16 10 6 5 18 17 15 14
h=4,i=16,j=12: 2 1 9 7 11 3 12 8 6 4 16 10 13 5 18 17 15 14
h=4,i=16,j=8: 2 1 9 7 6 3 12 8 11 4 16 10 13 5 18 17 15 14
h=4,i=16: 2 1 9 7 6 3 12 8 11 4 16 10 13 5 18 17 15 14
h=4,i=17: 2 1 9 7 6 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=1,j=1: 1 2 9 7 6 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=1: 1 2 9 7 6 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=2: 1 2 9 7 6 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=3,j=3: 1 2 7 9 6 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=3: 1 2 7 9 6 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=4,j=4: 1 2 7 6 9 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=4,j=3: 1 2 6 7 9 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=4: 1 2 6 7 9 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=5,j=5: 1 2 6 7 3 9 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=5,j=4: 1 2 6 3 7 9 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=5,j=3: 1 2 3 6 7 9 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=5: 1 2 3 6 7 9 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=6: 1 2 3 6 7 9 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=7,j=7: 1 2 3 6 7 9 8 12 11 4 16 10 13 5 18 17 15 14
h=1,i=7,j=6: 1 2 3 6 7 8 9 12 11 4 16 10 13 5 18 17 15 14
h=1,i=7: 1 2 3 6 7 8 9 12 11 4 16 10 13 5 18 17 15 14
h=1,i=8,j=8: 1 2 3 6 7 8 9 11 12 4 16 10 13 5 18 17 15 14
h=1,i=8: 1 2 3 6 7 8 9 11 12 4 16 10 13 5 18 17 15 14
h=1,i=9,j=9: 1 2 3 6 7 8 9 11 4 12 16 10 13 5 18 17 15 14
h=1,i=9,j=8: 1 2 3 6 7 8 9 4 11 12 16 10 13 5 18 17 15 14
h=1,i=9,j=7: 1 2 3 6 7 8 4 9 11 12 16 10 13 5 18 17 15 14
h=1,i=9,j=6: 1 2 3 6 7 4 8 9 11 12 16 10 13 5 18 17 15 14
h=1,i=9,j=5: 1 2 3 6 4 7 8 9 11 12 16 10 13 5 18 17 15 14
h=1,i=9,j=4: 1 2 3 4 6 7 8 9 11 12 16 10 13 5 18 17 15 14
h=1,i=9: 1 2 3 4 6 7 8 9 11 12 16 10 13 5 18 17 15 14
h=1,i=10: 1 2 3 4 6 7 8 9 11 12 16 10 13 5 18 17 15 14
h=1,i=11,j=11: 1 2 3 4 6 7 8 9 11 12 10 16 13 5 18 17 15 14
h=1,i=11,j=10: 1 2 3 4 6 7 8 9 11 10 12 16 13 5 18 17 15 14
h=1,i=11,j=9: 1 2 3 4 6 7 8 9 10 11 12 16 13 5 18 17 15 14
h=1,i=11: 1 2 3 4 6 7 8 9 10 11 12 16 13 5 18 17 15 14
h=1,i=12,j=12: 1 2 3 4 6 7 8 9 10 11 12 13 16 5 18 17 15 14
h=1,i=12: 1 2 3 4 6 7 8 9 10 11 12 13 16 5 18 17 15 14
h=1,i=13,j=13: 1 2 3 4 6 7 8 9 10 11 12 13 5 16 18 17 15 14
h=1,i=13,j=12: 1 2 3 4 6 7 8 9 10 11 12 5 13 16 18 17 15 14
h=1,i=13,j=11: 1 2 3 4 6 7 8 9 10 11 5 12 13 16 18 17 15 14
h=1,i=13,j=10: 1 2 3 4 6 7 8 9 10 5 11 12 13 16 18 17 15 14
h=1,i=13,j=9: 1 2 3 4 6 7 8 9 5 10 11 12 13 16 18 17 15 14
h=1,i=13,j=8: 1 2 3 4 6 7 8 5 9 10 11 12 13 16 18 17 15 14
h=1,i=13,j=7: 1 2 3 4 6 7 5 8 9 10 11 12 13 16 18 17 15 14
h=1,i=13,j=6: 1 2 3 4 6 5 7 8 9 10 11 12 13 16 18 17 15 14
h=1,i=13,j=5: 1 2 3 4 5 6 7 8 9 10 11 12 13 16 18 17 15 14
h=1,i=13: 1 2 3 4 5 6 7 8 9 10 11 12 13 16 18 17 15 14
h=1,i=14: 1 2 3 4 5 6 7 8 9 10 11 12 13 16 18 17 15 14
h=1,i=15,j=15: 1 2 3 4 5 6 7 8 9 10 11 12 13 16 17 18 15 14
h=1,i=15: 1 2 3 4 5 6 7 8 9 10 11 12 13 16 17 18 15 14
h=1,i=16,j=16: 1 2 3 4 5 6 7 8 9 10 11 12 13 16 17 15 18 14
h=1,i=16,j=15: 1 2 3 4 5 6 7 8 9 10 11 12 13 16 15 17 18 14
h=1,i=16,j=14: 1 2 3 4 5 6 7 8 9 10 11 12 13 15 16 17 18 14
h=1,i=16: 1 2 3 4 5 6 7 8 9 10 11 12 13 15 16 17 18 14
h=1,i=17,j=17: 1 2 3 4 5 6 7 8 9 10 11 12 13 15 16 17 14 18
h=1,i=17,j=16: 1 2 3 4 5 6 7 8 9 10 11 12 13 15 16 14 17 18
h=1,i=17,j=15: 1 2 3 4 5 6 7 8 9 10 11 12 13 15 14 16 17 18
h=1,i=17,j=14: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
h=1,i=17: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
$ java ShellSort -d
データの個数を入力して下さい 18
11 3 16 7 13 4 9 17 2 5 12 8 15 1 18 10 6 14
h=4,i=4: 11 3 16 7 13 4 9 17 2 5 12 8 15 1 18 10 6 14
h=4,i=5: 11 3 16 7 13 4 9 17 2 5 12 8 15 1 18 10 6 14
h=4,i=6: 11 3 9 7 13 4 16 17 2 5 12 8 15 1 18 10 6 14
h=4,i=7: 11 3 9 7 13 4 16 17 2 5 12 8 15 1 18 10 6 14
h=4,i=8: 2 3 9 7 11 4 16 17 13 5 12 8 15 1 18 10 6 14
h=4,i=9: 2 3 9 7 11 4 16 17 13 5 12 8 15 1 18 10 6 14
h=4,i=10: 2 3 9 7 11 4 12 17 13 5 16 8 15 1 18 10 6 14
h=4,i=11: 2 3 9 7 11 4 12 8 13 5 16 17 15 1 18 10 6 14
h=4,i=12: 2 3 9 7 11 4 12 8 13 5 16 17 15 1 18 10 6 14
h=4,i=13: 2 1 9 7 11 3 12 8 13 4 16 17 15 5 18 10 6 14
h=4,i=14: 2 1 9 7 11 3 12 8 13 4 16 17 15 5 18 10 6 14
h=4,i=15: 2 1 9 7 11 3 12 8 13 4 16 10 15 5 18 17 6 14
h=4,i=16: 2 1 9 7 6 3 12 8 11 4 16 10 13 5 18 17 15 14
h=4,i=17: 2 1 9 7 6 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=1: 1 2 9 7 6 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=2: 1 2 9 7 6 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=3: 1 2 7 9 6 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=4: 1 2 6 7 9 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=5: 1 2 3 6 7 9 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=6: 1 2 3 6 7 9 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=7: 1 2 3 6 7 8 9 12 11 4 16 10 13 5 18 17 15 14
h=1,i=8: 1 2 3 6 7 8 9 11 12 4 16 10 13 5 18 17 15 14
h=1,i=9: 1 2 3 4 6 7 8 9 11 12 16 10 13 5 18 17 15 14
h=1,i=10: 1 2 3 4 6 7 8 9 11 12 16 10 13 5 18 17 15 14
h=1,i=11: 1 2 3 4 6 7 8 9 10 11 12 16 13 5 18 17 15 14
h=1,i=12: 1 2 3 4 6 7 8 9 10 11 12 13 16 5 18 17 15 14
h=1,i=13: 1 2 3 4 5 6 7 8 9 10 11 12 13 16 18 17 15 14
h=1,i=14: 1 2 3 4 5 6 7 8 9 10 11 12 13 16 18 17 15 14
h=1,i=15: 1 2 3 4 5 6 7 8 9 10 11 12 13 16 17 18 15 14
h=1,i=16: 1 2 3 4 5 6 7 8 9 10 11 12 13 15 16 17 18 14
h=1,i=17: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
[nitta@ni java]$ java ShellSort -d2
データの個数を入力して下さい 18
11 3 16 7 13 4 9 17 2 5 12 8 15 1 18 10 6 14
h=4,i=4: 11 3 16 7 13 4 9 17 2 5 12 8 15 1 18 10 6 14
h=4,i=5: 11 3 16 7 13 4 9 17 2 5 12 8 15 1 18 10 6 14
h=4,i=6,j=6: 11 3 9 7 13 4 16 17 2 5 12 8 15 1 18 10 6 14
h=4,i=6: 11 3 9 7 13 4 16 17 2 5 12 8 15 1 18 10 6 14
h=4,i=7: 11 3 9 7 13 4 16 17 2 5 12 8 15 1 18 10 6 14
h=4,i=8,j=8: 11 3 9 7 2 4 16 17 13 5 12 8 15 1 18 10 6 14
h=4,i=8,j=4: 2 3 9 7 11 4 16 17 13 5 12 8 15 1 18 10 6 14
h=4,i=8: 2 3 9 7 11 4 16 17 13 5 12 8 15 1 18 10 6 14
h=4,i=9: 2 3 9 7 11 4 16 17 13 5 12 8 15 1 18 10 6 14
h=4,i=10,j=10: 2 3 9 7 11 4 12 17 13 5 16 8 15 1 18 10 6 14
h=4,i=10: 2 3 9 7 11 4 12 17 13 5 16 8 15 1 18 10 6 14
h=4,i=11,j=11: 2 3 9 7 11 4 12 8 13 5 16 17 15 1 18 10 6 14
h=4,i=11: 2 3 9 7 11 4 12 8 13 5 16 17 15 1 18 10 6 14
h=4,i=12: 2 3 9 7 11 4 12 8 13 5 16 17 15 1 18 10 6 14
h=4,i=13,j=13: 2 3 9 7 11 4 12 8 13 1 16 17 15 5 18 10 6 14
h=4,i=13,j=9: 2 3 9 7 11 1 12 8 13 4 16 17 15 5 18 10 6 14
h=4,i=13,j=5: 2 1 9 7 11 3 12 8 13 4 16 17 15 5 18 10 6 14
h=4,i=13: 2 1 9 7 11 3 12 8 13 4 16 17 15 5 18 10 6 14
h=4,i=14: 2 1 9 7 11 3 12 8 13 4 16 17 15 5 18 10 6 14
h=4,i=15,j=15: 2 1 9 7 11 3 12 8 13 4 16 10 15 5 18 17 6 14
h=4,i=15: 2 1 9 7 11 3 12 8 13 4 16 10 15 5 18 17 6 14
h=4,i=16,j=16: 2 1 9 7 11 3 12 8 13 4 16 10 6 5 18 17 15 14
h=4,i=16,j=12: 2 1 9 7 11 3 12 8 6 4 16 10 13 5 18 17 15 14
h=4,i=16,j=8: 2 1 9 7 6 3 12 8 11 4 16 10 13 5 18 17 15 14
h=4,i=16: 2 1 9 7 6 3 12 8 11 4 16 10 13 5 18 17 15 14
h=4,i=17: 2 1 9 7 6 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=1,j=1: 1 2 9 7 6 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=1: 1 2 9 7 6 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=2: 1 2 9 7 6 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=3,j=3: 1 2 7 9 6 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=3: 1 2 7 9 6 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=4,j=4: 1 2 7 6 9 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=4,j=3: 1 2 6 7 9 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=4: 1 2 6 7 9 3 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=5,j=5: 1 2 6 7 3 9 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=5,j=4: 1 2 6 3 7 9 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=5,j=3: 1 2 3 6 7 9 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=5: 1 2 3 6 7 9 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=6: 1 2 3 6 7 9 12 8 11 4 16 10 13 5 18 17 15 14
h=1,i=7,j=7: 1 2 3 6 7 9 8 12 11 4 16 10 13 5 18 17 15 14
h=1,i=7,j=6: 1 2 3 6 7 8 9 12 11 4 16 10 13 5 18 17 15 14
h=1,i=7: 1 2 3 6 7 8 9 12 11 4 16 10 13 5 18 17 15 14
h=1,i=8,j=8: 1 2 3 6 7 8 9 11 12 4 16 10 13 5 18 17 15 14
h=1,i=8: 1 2 3 6 7 8 9 11 12 4 16 10 13 5 18 17 15 14
h=1,i=9,j=9: 1 2 3 6 7 8 9 11 4 12 16 10 13 5 18 17 15 14
h=1,i=9,j=8: 1 2 3 6 7 8 9 4 11 12 16 10 13 5 18 17 15 14
h=1,i=9,j=7: 1 2 3 6 7 8 4 9 11 12 16 10 13 5 18 17 15 14
h=1,i=9,j=6: 1 2 3 6 7 4 8 9 11 12 16 10 13 5 18 17 15 14
h=1,i=9,j=5: 1 2 3 6 4 7 8 9 11 12 16 10 13 5 18 17 15 14
h=1,i=9,j=4: 1 2 3 4 6 7 8 9 11 12 16 10 13 5 18 17 15 14
h=1,i=9: 1 2 3 4 6 7 8 9 11 12 16 10 13 5 18 17 15 14
h=1,i=10: 1 2 3 4 6 7 8 9 11 12 16 10 13 5 18 17 15 14
h=1,i=11,j=11: 1 2 3 4 6 7 8 9 11 12 10 16 13 5 18 17 15 14
h=1,i=11,j=10: 1 2 3 4 6 7 8 9 11 10 12 16 13 5 18 17 15 14
h=1,i=11,j=9: 1 2 3 4 6 7 8 9 10 11 12 16 13 5 18 17 15 14
h=1,i=11: 1 2 3 4 6 7 8 9 10 11 12 16 13 5 18 17 15 14
h=1,i=12,j=12: 1 2 3 4 6 7 8 9 10 11 12 13 16 5 18 17 15 14
h=1,i=12: 1 2 3 4 6 7 8 9 10 11 12 13 16 5 18 17 15 14
h=1,i=13,j=13: 1 2 3 4 6 7 8 9 10 11 12 13 5 16 18 17 15 14
h=1,i=13,j=12: 1 2 3 4 6 7 8 9 10 11 12 5 13 16 18 17 15 14
h=1,i=13,j=11: 1 2 3 4 6 7 8 9 10 11 5 12 13 16 18 17 15 14
h=1,i=13,j=10: 1 2 3 4 6 7 8 9 10 5 11 12 13 16 18 17 15 14
h=1,i=13,j=9: 1 2 3 4 6 7 8 9 5 10 11 12 13 16 18 17 15 14
h=1,i=13,j=8: 1 2 3 4 6 7 8 5 9 10 11 12 13 16 18 17 15 14
h=1,i=13,j=7: 1 2 3 4 6 7 5 8 9 10 11 12 13 16 18 17 15 14
h=1,i=13,j=6: 1 2 3 4 6 5 7 8 9 10 11 12 13 16 18 17 15 14
h=1,i=13,j=5: 1 2 3 4 5 6 7 8 9 10 11 12 13 16 18 17 15 14
h=1,i=13: 1 2 3 4 5 6 7 8 9 10 11 12 13 16 18 17 15 14
h=1,i=14: 1 2 3 4 5 6 7 8 9 10 11 12 13 16 18 17 15 14
h=1,i=15,j=15: 1 2 3 4 5 6 7 8 9 10 11 12 13 16 17 18 15 14
h=1,i=15: 1 2 3 4 5 6 7 8 9 10 11 12 13 16 17 18 15 14
h=1,i=16,j=16: 1 2 3 4 5 6 7 8 9 10 11 12 13 16 17 15 18 14
h=1,i=16,j=15: 1 2 3 4 5 6 7 8 9 10 11 12 13 16 15 17 18 14
h=1,i=16,j=14: 1 2 3 4 5 6 7 8 9 10 11 12 13 15 16 17 18 14
h=1,i=16: 1 2 3 4 5 6 7 8 9 10 11 12 13 15 16 17 18 14
h=1,i=17,j=17: 1 2 3 4 5 6 7 8 9 10 11 12 13 15 16 17 14 18
h=1,i=17,j=16: 1 2 3 4 5 6 7 8 9 10 11 12 13 15 16 14 17 18
h=1,i=17,j=15: 1 2 3 4 5 6 7 8 9 10 11 12 13 15 14 16 17 18
h=1,i=17,j=14: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
h=1,i=17: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
|